


김범준(Beomjoon Kim)(KAIST AI 대학원) / beomjoon.kim at kaist.ac.kr
2021-06-09
|
1. 본인의 연구에 대해서 자세한 소개를 부탁 드립니다. - 저는 모바일 매니퓰레이터의 지능을 개발합니다. 제 연구는 크게 두 가지 방향이 있는데, 첫째는 매니퓰레이션을 위한 인지입니다. 물체를 한 지점에서 다른 지점으로 옮기는 간단한 일을 생각해봅시다. 사람은 이 물체를 인지하고 물체의 물리적 성질을 측정해낸 뒤 목적 달성을 위한 동작을 계획하는 데 능숙합니다. 하지만 아직 “로봇에게 물체를 어떻게 인지하고 인지한 것을 바탕으로 어떻게 동작을 효율적으로 계산하는가?” 라는 문제는 아직 미해결 문제입니다. 저희는 여기에 초점을 맞춰 로봇이 효율적으로 세상을 인지하고 매니퓰레이션 계획을 세우기 위한 인지-매니퓰레이션 방법론을 강구하고 있습니다. 두 번째는 효율적인 계획을 위한 학습법입니다. 인간은 주어진 목적을 달성하기 위해 계획을 세우는 데 익숙합니다. 대전에서 서울까지 길을 계획 한다든가, 혹은 주방에서 설거지를 한다든가 하는 예가 있겠지요. 인간은 처음 해보는 일에 한해서는 취할 수 있는 행동들의 결과들을 모두 고려해보며 다소 느리게 계획을 연산합니다. 하지만 여러 번 계획을 세워보고 경험이 쌓이면서 연산이 점점 더 빨라지고, 후에는 많은 생각을 해보지 않아도 빠르게 계획을 세울 수가 있죠. 이와 대비해 현재 학계에는 연구되는 방법론들은 대개 순수학습법들과 순수 계획법 중 한 가지를 택합니다. 제 연구는 이 두 가지 기법들을 섞어 마치 인간처럼 로봇이 처음에는 계획법에 의존하다가 경험이 쌓이면 학습된 것을 바탕으로 계획 연산을 가속화 하는 것에 초점을 맞추고 있습니다. 2. 로봇팔이 여러 형태의 복잡한 물건을 집어서 옮기는 영상들을 보았습니다. 이 연구에서 현재 가장 중점을 두고 연구하고 계신 내용은 무엇인가요? 또한 어떤 해결해야할 어려운 문제가 있는지 궁금합니다.  - 이 연구에서 가장 중점적인 부분은 인지와 매니퓰레이션의 결합입니다. 위에 말했듯 로봇은 센서로 물체를 보고, 인지 알고리즘을 통해 물체의 성질을 측정해낸 뒤 그에 알맞은 매니퓰레이션 액션을 계획해야 합니다. 기존에는 인지 소프트웨어 모듈과 계획 모듈을 따로 두고 인지 모듈의 출력값을 기반으로 계획을 세우는 방식을 택했습니다. 이 방법론의 문제점은 로봇이 인지해야 하는 것을 사람이 일일이 지정해줘야 한다는 것입니다. 예를 들어 물체를 밀거나 당긴다면 물체의 형태를 인지해야 하고, 물체를 던지는 행동을 한다면 물체의 마찰력은 무시한다던지 등등 여러 상황을 고려해 사람이 인지 모듈의 출력값을 정의해야 합니다. 이는 번거로울 뿐만 아니라 사람이 로봇에게 불필요한 것을 인지하게 하거나, 혹은 필요한 것을 놓쳐버린다면 로봇의 계획 연산이 불가능해진다는 단점이 있습니다.
- 이 연구에서 가장 중점적인 부분은 인지와 매니퓰레이션의 결합입니다. 위에 말했듯 로봇은 센서로 물체를 보고, 인지 알고리즘을 통해 물체의 성질을 측정해낸 뒤 그에 알맞은 매니퓰레이션 액션을 계획해야 합니다. 기존에는 인지 소프트웨어 모듈과 계획 모듈을 따로 두고 인지 모듈의 출력값을 기반으로 계획을 세우는 방식을 택했습니다. 이 방법론의 문제점은 로봇이 인지해야 하는 것을 사람이 일일이 지정해줘야 한다는 것입니다. 예를 들어 물체를 밀거나 당긴다면 물체의 형태를 인지해야 하고, 물체를 던지는 행동을 한다면 물체의 마찰력은 무시한다던지 등등 여러 상황을 고려해 사람이 인지 모듈의 출력값을 정의해야 합니다. 이는 번거로울 뿐만 아니라 사람이 로봇에게 불필요한 것을 인지하게 하거나, 혹은 필요한 것을 놓쳐버린다면 로봇의 계획 연산이 불가능해진다는 단점이 있습니다.이와 반대로 저희가 택하는 방식은 뉴럴 네트워크가 센서 데이터에서 접촉 행동을 바로 예측하게 함으로써 예측을 위해 무엇을 인지해야 하는지 네트워크가 데이터로부터 학습하게 했습니다. 이 기법은 사람이 아닌 데이터를 기반으로 무엇을 인지할지 학습함으로써 사람의 부담을 덜어준다는 장점이 있습니다. 하지만 이 방법론도 완벽하지는 않습니다. 저희가 고려한 상황은 로봇이 한가지 물체를 다루는 문제였으며, 물체가 여러 개 있고 시야 가림 현상 등이 있는 문제는 아직 풀지 못합니다. 이 부분이 앞으로 저희가 포커스를 맞출 분야 중 하나입니다. 3. 추가로 여러가지 실험에 대한 소개를 부탁드립니다. - 저는 향후 5년간 로봇이 가장 큰 임팩트를 줄 수 있는 분야가 물류라고 생각합니다. 물류창고는 사람이 사는 공간보다는 변동성이 훨씬 적으면서도 기존 산업용 로봇들이 사용되던 공장보다는 변동성이 높아 이제 막 첫걸음을 시작하는 지능형 모바일 매니퓰레이터들을 시험하기에 가장 좋은 환경이라 생각합니다. 게다가 시장성도 매우 크고요. 이 관찰들에 기반해서 저는 물류창고에서 로봇이 풀 수 있는 문제들에 중점을 두고 실험을 해왔습니다. 이런 환경에서 제가 중점적인 다룬 문제 중 하나는 움직일 수 있는 장애물들 사이에 상자 채우기 (Bin packing among movable obstacles)입니다. 이를 위해 갖가지 학습법 및 계획법을 개발해 Fig. 2 에서 보이는 환경에서 실험을 했습니다. 또 이런 물류 창고에서 중요한 능력 중 하나는 여러 물체를 다룰 수 있는 능력입니다. 이를 위해 여러 매니퓰레이션 스킬을 사용해 갖가지 물체를 센서로 인지하고 동작 계획을 세워 목적을 달성하는 실험을 했습니다.(Fig. 2 참조) 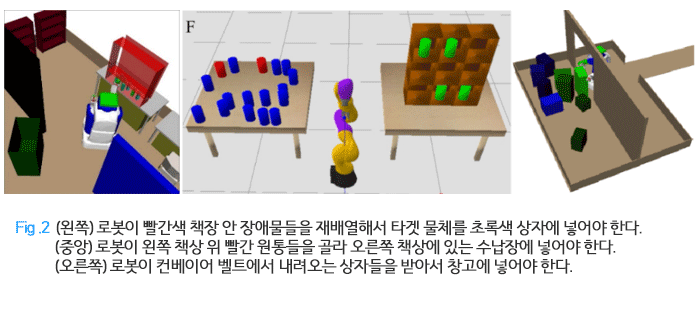 4. 앞으로 진행할 연구 방향이나 목표가 있으시다면? - 앞으로 세 가지 방향에 중점을 맞추고 있습니다. 첫째는 시뮬레이터 개발입니다. 로봇이 여러 정형화되지 않은 환경에서 쓰이려면 학습이 필수적인데, 이를 위해 많은 데이터가 필요할 것입니다. 이런 데이터를 로봇이 쓰일 환경에서 직접 활동하며 데이터를 얻는 것은 비효율적이고 위험합니다. 따라서 이런 데이터를 손쉽게 얻기 위해 여러 환경을 시뮬레이트 할 수 있는 시뮬레이터 구현이 필수적이라 보고, 여러 환경에서 로봇이 환경과 상호작용 할 수 있는 효율적인 시뮬레이터를 구현할 예정입니다. 두 번째 방향은 로봇에게 환경과 상호작용하며 인지를 할 수 있게 하는 능력을 부여하는 것입니다. 현재 인지 알고리즘들은 대다수 컴퓨터 비전 학계에서 나온 알고리즘들로, 하나의 이미지를 통해 기계가 인지를 해야 합니다. 이와 대조적으로 사람은 자신의 환경을 자신의 행동을 통해 변화시키고 탐험해서 시야 가림 현상이나 물체가 당장 눈앞에 없는 복잡한 상황 속에서도 인지를 할 수가 있습니다. 안타깝게도 로봇에게는 아직 이런 효율적 상호작용 인지를 할 수 있는 기법이 부재한 상황이며, 이것이 우리가 두 번째로 집중할 문제입니다. 그리고 마지막으로는 효율적 매니퓰레이션 계획을 위한 학습입니다. 알파고는 가치함수와 정책 함수를 경험을 통해 학습함으로써 Monte Carlo Tree Search 계획법이 더 빠르게 계획을 연산하도록 했습니다. 이를 토대로 인간보다 더 뛰어난 바둑 실력을 갖게 됐죠. 저희는 이 직관을 로봇이 다수의 물체를 다뤄야 하는 계획 문제에 적용하고자 합니다. 여기에는 갖가지 난제가 있는데, 그중 하나가 바둑판이 아닌 다수의 물체와 로봇이 있는 환경을 어떻게 나타낼지가 한가지이고, 두 번째는 바둑에는 크지만 유한한 경우의 수가 있지만, 로봇에게는 무한한 경우의 수가 있다는 점입니다. 현재 이 두 가지 난제를 해결하는 데 초점을 맞추고 있습니다. 5. 지능형 모바일 조작연구실(iM ^ 2)랩에 대해서 소개를 부탁드리며, 어떤 학생들이 지원하면 좋을지 비젼을 제시해 주신다면? - 우리 연구실은 물류창고, 집안, 재난 현장, 병원 등에서 사람을 도울 수 있는 다용도 지능형 모바일 매니퓰레이터를 개발하는 것을 궁극적 목표로 두고 있습니다. 이는 현재 세계가 빠르게 고령화 사회에 진입하고 있으며 이에 따라 극심한 노동 인구 난과 육체노동 기피 현상, 그리고 가파른 임금 상승 등이 일어날 것이고, 이에 따라 향후 10년 안에 우리 삶에 로봇이 필수적이게 될 것이라는 비전에 기반합니다. 이런 비전을 저와 함께 이뤄나가시고 기술의 열정이 있는 분이라면 모두 지원해 주셨으면 좋겠습니다. 6. 영향을 받은 연구자가 있다면? 또한 어떤 영향을 받으셨는지 궁금합니다. - 가장 큰 영향은 역시 박사 지도 교수님이셨던 Leslie Pack Kaelbling과 Tomas Lozano-Perez 교수님께 받았습니다. 두 분께서 제게 남긴 가장 큰 영향은 위대한 예술가처럼 연구하라는 것입니다. 예술 작품을 만드는 데는 여러 가지 단계가 들어갑니다. 작품 구상, 밑 작업, 그리고 수많은 시행착오를 거쳐서 하나의 작품이 탄생합니다. 위대한 예술가는 자신의 작품에 대한 그 누구보다 높은 기준을 갖고, 이 기준에 맞춰 각 단계에서 타협하지 않고 잘못된 점이 있으면 끈질기게 자신의 작품을 고쳐 나갑니다. 또 위대한 예술가는 다른 예술가들과 끊임없이 교류하며 자신의 작품에 현 시류를 반영하거나 혹은 시류를 뛰어넘는 작품을 만들기도 하죠. 대표적인 예로는 피카소가 있습니다. 이와 마찬가지로 연구자는 아이디어 구상, 구현, 그리고 실험을 통해 아이디어를 검증하고 고쳐 나가는 단계를 거쳐 하나의 논문을 써냅니다. 학회를 가고 다른 연구자들과 끊임없이 교류를 해서 연구의 시류를 파악하고, 그 시류를 자신의 논문에 녹여내거나 혹은 시류를 뛰어넘는 논문을 발표합니다. 위대한 예술가가 그러하듯 위대한 연구자가 되려면 자신의 논문에 대해 그 누구보다 높은 기준을 갖고, 그 기준에 도달하기 위해 타협하지 않아야 하며, 시류를 끊임없이 파악하고 또 뛰어넘으려 시도해야 합니다. 7. 연구활동 하시면서 평소 느끼신 점 또는 자부심, 보람 - 위에 시류를 파악하고 시류를 뛰어넘는 연구를 시도해야 한다고 했는데, 제 박사 때 두 번째 논문이 그러했던 것 같습니다. 2017년 ICRA에 냈던 Learning to guide task and motion planning이라는 논문이 최고 인지 로봇 상 후보에 올랐었는데, 그 당시 후보로 올랐던 Chelsea Finn 교수님의 논문을 비롯해 다른 후보 논문들이 모두 뉴럴 네트워크를 사용하는 방식을 택했습니다. 저희가 유일하게 다른 방법을 제안했는데, 이렇게 시류에 휩쓸리지 않고 새로운 방법에 치중한 덕분에 저희 논문이 그 상을 수상을 했습니다. 아마 저희 교수님의 위대한 예술가처럼 연구하라는 가르침이 없었다면 제가 받지 못했을 상이라고 생각합니다. 8. 이 분야로 진학 하려는 학생들에게 조언을 해 주신다면? - 먼저 문제를 발견하시고 방법론을 찾으시라는 조언을 드리고 싶습니다. 우리 연구실에 지원해주시는 많은 분이 “X라는 방법을 사용하는 연구를 하고 싶다”라는 말씀을 많이 하십니다. 주로 여기 X는 강화학습인 경우가 많고요. 이렇게 방법론에 치우친 연구는 목표가 단지 state-of-the-art를 이기는 것 뿐이기에 재미도 없고, 무엇보다 의미 있고 세상을 바꾸는 연구를 하기가 힘들어집니다. 이것보다는 먼저 생각만 해도 가슴이 뛰고, 풀린다면 세상을 뒤바꿀 것 같은 로보틱스 문제를 생각해 보세요. 그런 문제를 푸는 것을 목표로 학습하고 연구를 하신다면 훨씬 더 유의미한 연구를 하실 수 있을 것이고, 또 설사 연구가 뜻대로 되지 않는다고 하더라도 자신의 사명감이 여러분을 앞으로 나아가게 할 겁니다. * 김범준 교수의 최근(대표)논문 [1] Monte Carlo Tree Search in continuous spaces using Voronoi optimistic optimization with regret bounds (AAAI), 2020. (Oral) [2] Learning value functions with relational state representations for guiding task-and-motion planning (CoRL) 2019. [3] Regret bounds for meta Bayesian optimization with an unknown Gaussian process prior (NeurIPS) 2018. (Spotlight) [4] Learning to guide task and motion planning using score-space representation (ICRA) 2017 (Winner of Best Cognitive Robotics Paper Award) [5] Learning from limited demonstrations (NeurIPS) 2013 (Spotlight) |
- mobile-manipulation
- artificial intelligence
- task and motion planning




전체댓글 0













